Jess Park provided a timely demonstration of her qualities as her superb, long-range goal capped off a confident individual performance that helped Manchester United progress to the Women’s Champions League quarter-finals with a resounding win over Atlético Madrid.
The German champions, Bayern Munich, will be Marc Skinner’s team’s quarter-final opponents, between 23 March and 1 April, with United reaching the last eight for the first time. That significant landmark for the club was fittingly accompanied by a special goal from Park, whose curling strike completed a 5-0 aggregate victory and boosted her chances of starting for England in March.
Continue reading...Men’s team edge tense semi-final battle 8-5
They go for gold in Saturday’s final against Canada
Great Britain’s men’s team will play for the curling gold night against Canada, after they beat Switzerland 8-5 in an extraordinarily tense semi-final.
The GB quartet, who only scraped through the round-robin stage because the Italians lost to the Swiss earlier in the day, had promised that they would be an entirely different proposition if they got to the knockout rounds and they were as good as their word. The Swiss had won all nine games they had played coming into this semi-final, but were soundly beaten by Bruce Mouat and his team of Grant Hardie, Hammy McMillan and Bobby Lammie.
Continue reading...Apple’s feature, which connects phone to satellite, helped first responders find survivors as they waited under tarp
California’s deadliest avalanche killed at least eight people in a ski group near Lake Tahoe on Tuesday. The six survivors used the iPhone’s emergency SOS feature to help first responders find them as they waited under a tarp and discovered some of the bodies, according to the Nevada county sheriff. Apple’s feature, introduced in 2022, allows users to text law enforcement, even if there’s no cell service or wifi by connecting the phone to a satellite.
First responders reached the skiers’ location and learned of the six survivors based on conversations held through the feature, Sheriff Shannan Moon said at a press conference on Wednesday.
Continue reading...
“For me, it always starts with joy,” explains Aunia Kahn. The Detroit-based artist uses a handful of materials—gouache, pastels, pencils, and gold ink—to create rich, velvety portraits that evoke folk art patterns, surrealist themes, and celestial iconography.
Reclaiming the importance of play in the creative process has been a powerful catalyst for Kahn, who had previously experienced a loss of joy in making amid life-threatening health challenges. “That playfulness led me straight back to my roots, to growing up in Michigan and spending time in Canada, to the German and Polish folk art that filled my grandparents’ home,” she says. “I realized that world of bold color, rich pattern, and maximalist symbolism had already shaped my home, my wardrobe, and the way I moved through life. My art just needed to catch up.”

When she’s not in the studio, Kahn is busy curating exhibitions as the co-owner of Poetic Tiger Gallery and is Editor-in-Chief of Hyperlux Magazine. Find more work on the artist’s website, and keep up with her many adventures on Instagram.





Do stories and artists like this matter to you? Become a Colossal Member today and support independent arts publishing for as little as $7 per month. The article Aunia Kahn’s Lush Portraits Depict a Playful Inner Landscape appeared first on Colossal.
The downstream effects are visible across Europe's flagship industries. When Audi closed its Brussels factory after cancelling the E-Tron SUV in 2024, severance ran to $718 million -- over $235,000 per employee and more than the cost of writing off the plant's physical assets. Volkswagen spent $50 billion on its electric vehicle lineup, failed to develop competitive software internally, and ultimately paid up to $5 billion for access to American startup Rivian's technology.
Between 2012 and 2016, 79% of all startup acquisitions tracked by Crunchbase took place in the US. The essay points to Denmark, Austria and Switzerland as countries that have found a middle path -- generous unemployment insurance and portable severance accounts that protect workers without penalizing employers for taking risks.
Read more of this story at Slashdot.
The system writes data by firing laser pulses lasting just 10^-15 seconds to create tiny features called voxels inside the glass, each capable of storing more than one bit, and reads it back using phase contrast microscopy paired with a convolutional neural network trained to interpret the images. Writing remains the main bottleneck -- four lasers operating simultaneously achieve 66 megabits per second, meaning a full slab would take over 150 hours to write, though the team believes adding more lasers is feasible.
Read more of this story at Slashdot.
People have used hacks and loopholes to abuse search engines for decades. Google has sophisticated protections in place, and the company says the accuracy of AI Overviews is on par with other search features it introduced years ago. But experts say AI tools have undone a lot of the tech industry's work to keep people safe. These AI tricks are so basic they're reminiscent of the early 2000s, before Google had even introduced a web spam team.... Not only is AI easier to fool, but experts worry that users are more likely to fall for it. With traditional search results you had to go to a website to get the information. "When you have to actually visit a link, people engage in a little more critical thought," says Quintin. "If I go to your website and it says you're the best journalist ever, I might think, 'well yeah, he's biased'." But with AI, the information usually looks like it's coming straight from the tech company. --- It appears to me that publishing the article in the BBC may have spoiled the effect. When I did a Google search, the AI summary gave me a digest of the article instead of parroting the original blog post.
'Holtz likens paleontologists' efforts to decipher how the dinosaurs lived based on scant evidence to a famous parable in which blind scholars encounter an elephant for the first time. One touches the trunk and proclaims it a snake. Another touches a leg and proclaims it a tree trunk. "Only in this case, the elephant's been blown to smithereens," Holtz says. 'Previously here and here.
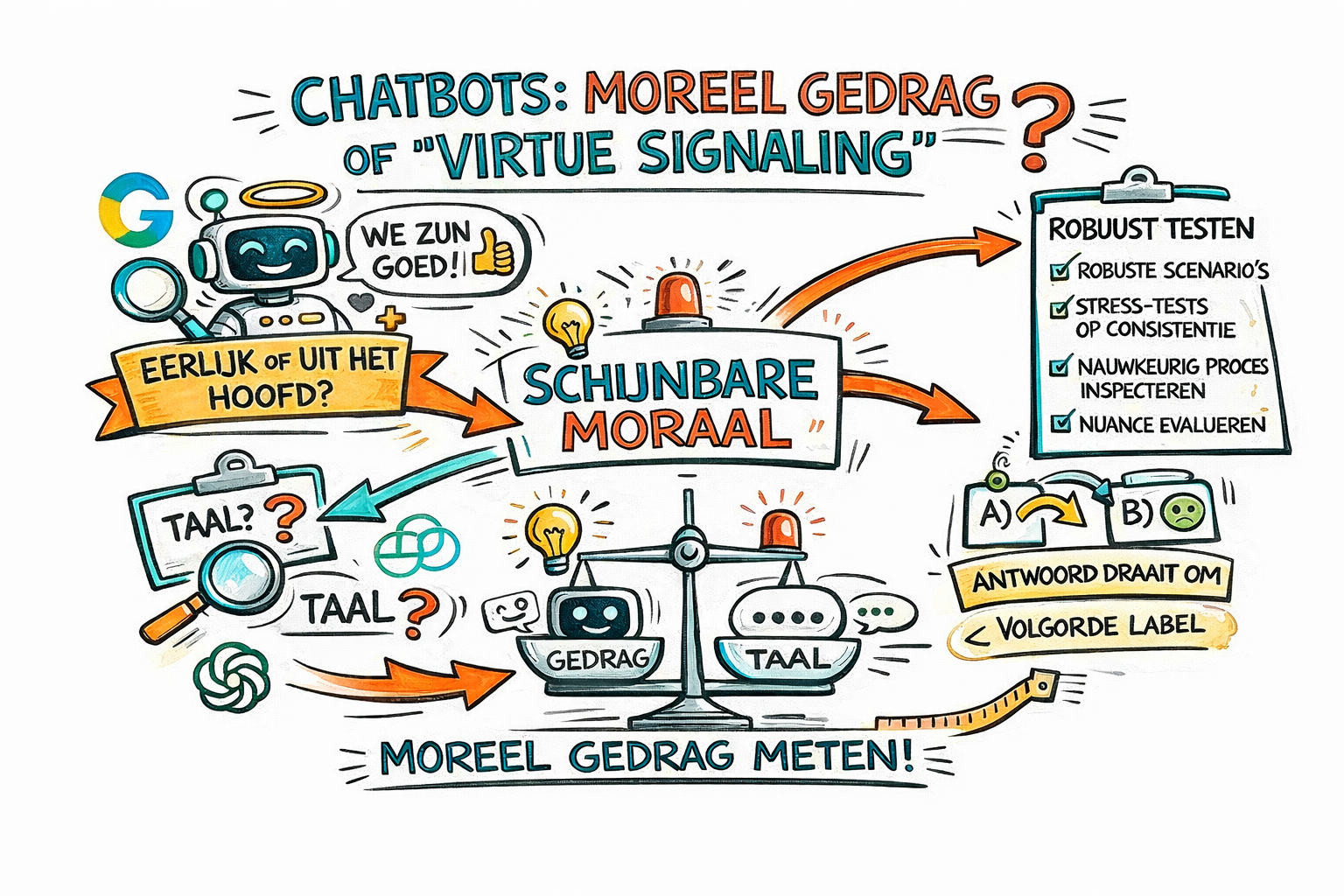
De publicatie “A roadmap for evaluating moral competence in large language models” in Nature deze maand bleef wat langer in mijn hoofd rondspoken.
Het startpunt van de publicatie is dat taalmodellen (large language models of LLM’s) steeds vaker worden gebruikt in situaties met een morele lading: advies, begeleiding, reflectie, soms zelfs als vervanging van menselijke expertise. En dan bijvoorbeeld in de vorm van een chatbot. Dat riep bij de auteurs de vraag op: is het wel terecht om te veronderstellen dat deze systemen moreel kunnen redeneren? En hoe kunnen we dat vaststellen? De auteurs maken daarbij een onderscheid tussen moral performance en moral competence. Een chatbot kan moreel overtuigend klinken, empathisch reageren en sociaal wenselijke antwoorden geven. Maar dat betekent nog niet dat het systeem moreel relevante overwegingen begrijpt of afweegt. Het kan net zo goed gaan om statistisch plausibele taalproductie.
Probleem 1: Het facsimile-probleem
Taalmodellen zijn ontworpen als next-token voorspellers. Dat betekent dat correcte antwoorden niet noodzakelijk voortkomen uit een intern redeneerproces dat structureel lijkt op menselijke redenering. Een model kan patronen reproduceren, betrouwbaar klinkende redeneringen genereren en ook redeneerstappen simuleren zonder bewijs dat de onderliggende mechanismen daadwerkelijk morele afwegingen representeren.
Daarom pleiten de auteurs voor adversarial testing: scenario’s die lijken op bekende morele casussen, maar waarin de normatieve structuur subtiel verandert. Zulke tests kunnen blootleggen of een model abstraheert of slechts herkent.
Probleem 2: Morele multidimensionaliteit + model-brittleness
Menselijke morele oordelen zijn contextgevoelig en afhankelijk van veel factoren tegelijk: principes, gevolgen, intenties, sociale rollen, maar ook irrelevante invloeden. Taalmodellen voegen daar een extra complicatie aan toe: “brittleness” (sorry, weet geen goede vertaling). Het betekent dat kleine wijzigingen in prompts (formulering, volgorde, labels, vraagtype) kunnen leiden tot andere morele conclusies, inconsistentie of soms zelfs tegengestelde antwoorden. Dit maakt traditionele goed/fout-evaluaties ontoereikend.
De voorgestelde oplossing van de auteurs is om parametrische evaluaties te gebruiken en te werken met acceptabele antwoord-ranges in plaats van binaire scores.
Probleem 3: Moreel pluralisme op wereldschaal
Er bestaat geen universeel moreel kader. Normen verschillen per cultuur, domein en waardensysteem. Van mensen verwachten we interne consistentie. Voor wereldwijd gebruikte AI-systemen is de eis anders: modellen moeten kunnen functioneren binnen meerdere legitieme morele kaders.
De publicatie introduceert daarom twee sleutelconcepten:
- Overton pluralism: meerdere redelijke antwoorden expliciteren
- Steerable pluralism: modelgedrag conditioneren op perspectief of waarden
Kernboodschap
De kernboodschap van het artikel is dat de vraag of een model werkelijk moreel redeneert een nieuw type benchmarks vereist.
Maar…
Dit gaat nog steeds uit van de veronderstelling dat het wellicht mogelijk is, dat het echt kan, dus niet uit van de aanname dat het taalmodellen zijn en simpelweg never nooit niet in staat zullen worden om echt moreel te redeneren. Want als dát je startpunt is, dan is dit hele onderzoek onzin en verspilling van middelen. Dan is de vraag namelijk niet hebben we wel de juiste meetinstrumenten om dat robuust te testen?